先决条件:
环境
- rhel 7.2
- jdk-8u102-linux-x64
- spark-2.0.2-bin-hadoop2.7
- Scala 2.11,注意:2.11.x 版本是不兼容的,见官网:http://spark.apache.org/docs/latest/。
准备 master 主机和 worker 分机
- server1 机器:10.8.26.197,master
- server2 机器:10.8.26.196,worker
- server3 机器:10.8.26.195,worker
修改 host
|
|
关闭所有节点机防火墙
|
|
启动集群
主节点
|
|
查看输出日志:
|
|
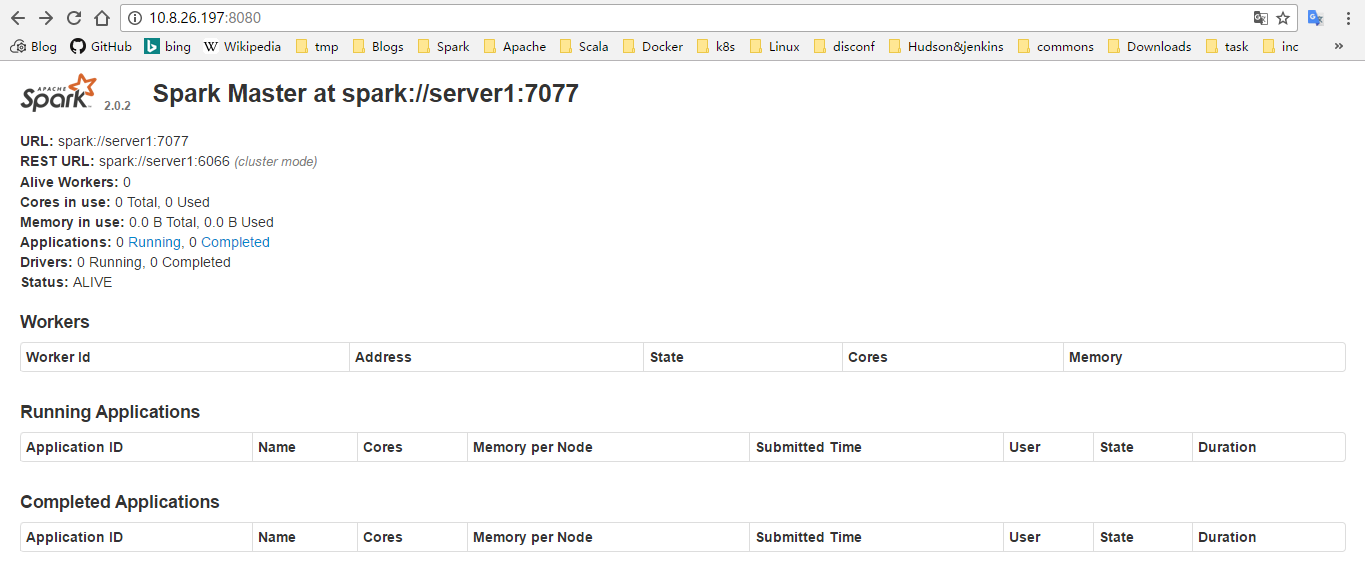
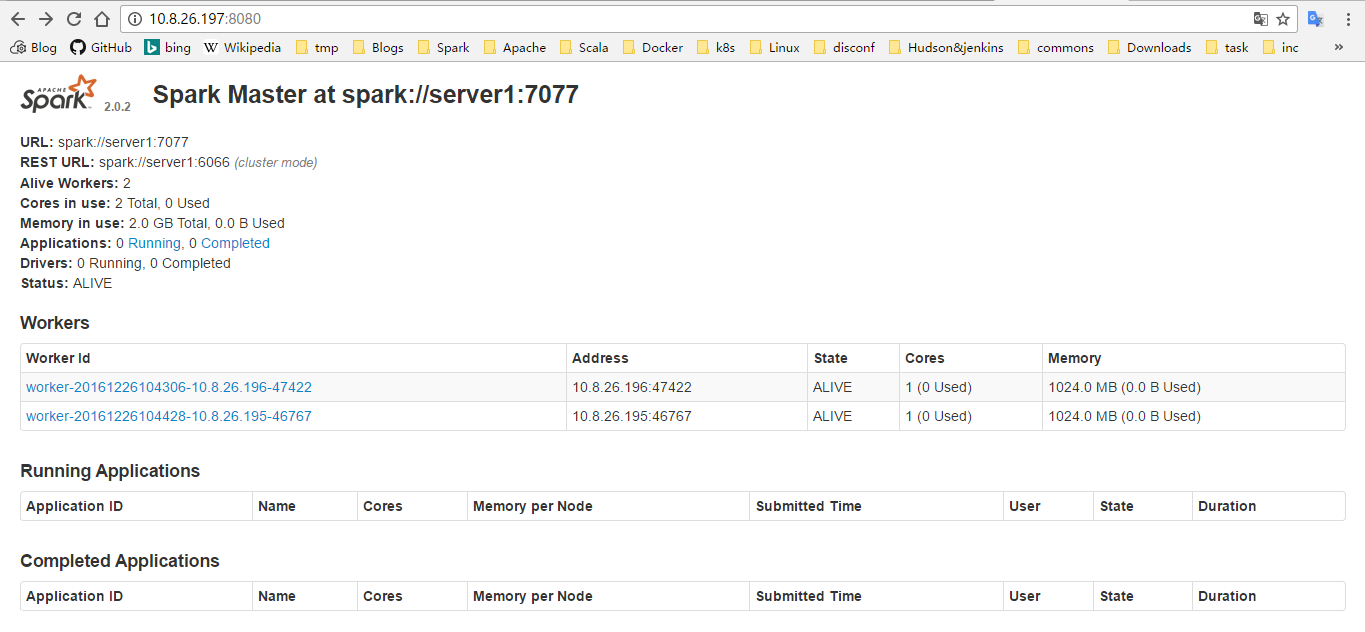
通过 master-ip:8080 访问 master 的 web UI
各 worker 节点
|
|
节点输出日志:
|
|
通过 master-ip:8080 访问 master 的 web UI
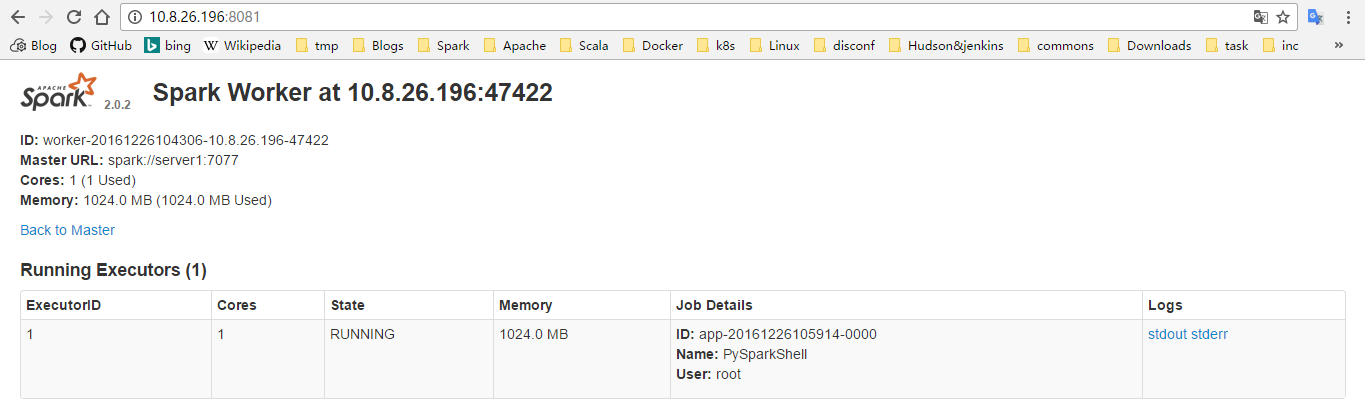
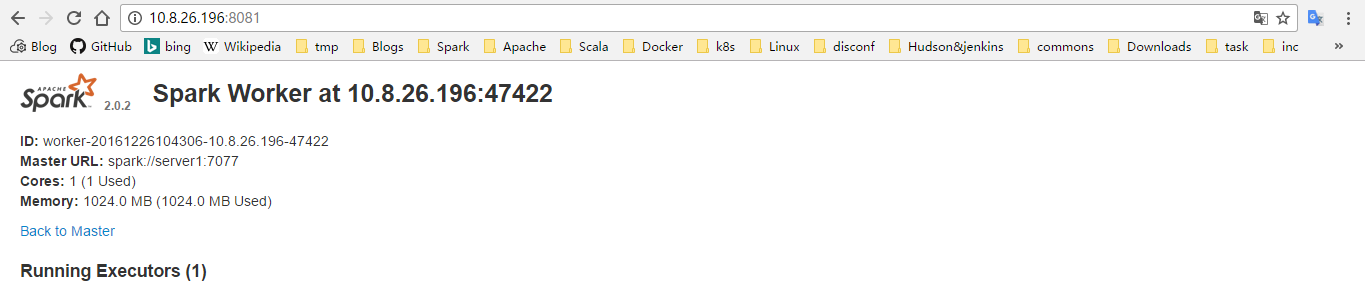
通过 worker-ip:8081 访问 worker 的 web UI
提交应用程序到集群
集成 shell 测试环境
切换至 bin 目录
|
|
进入运行在集群上的 spark 的 集成调试环境。
Python
|
|
以统计文本行数为例:
|
|
输出 README.md 中共有 99 行
scala
|
|
可以在 master 的 web 界面里面看到任务执行情况
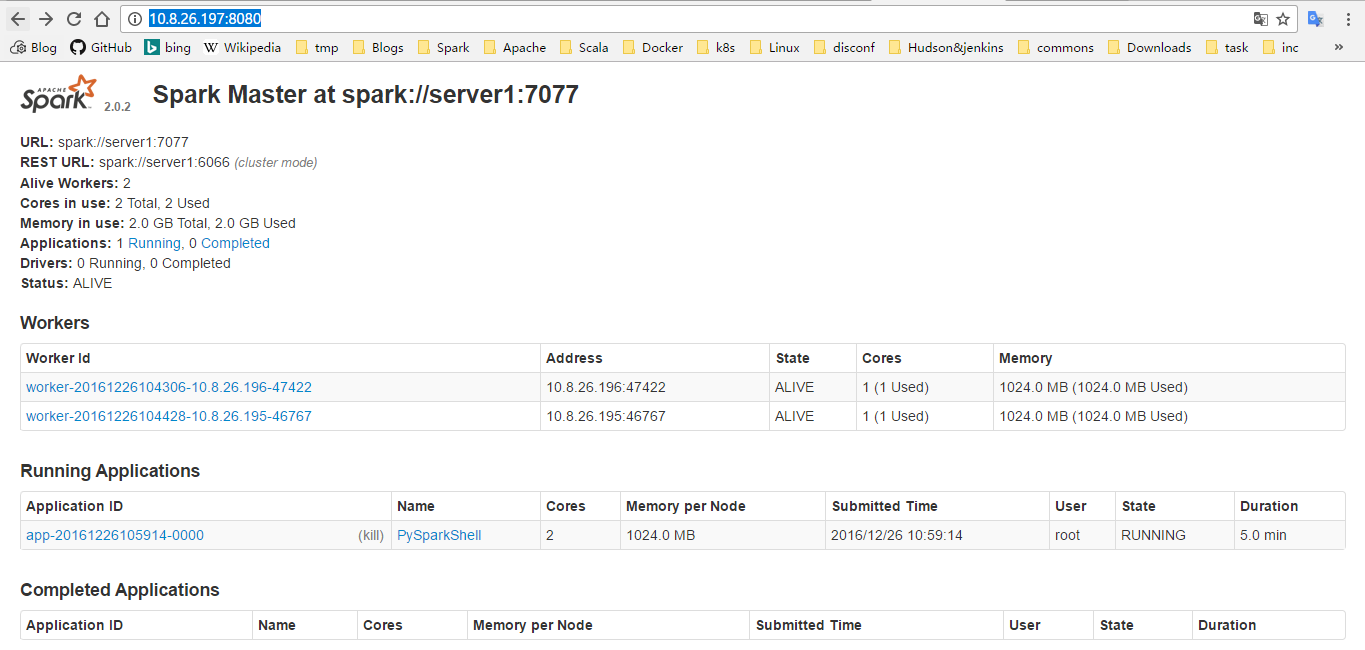
也可以在 worker 的 web 界面里面看单个 worker 的情况