环境准备
1. 服务器角色分配
| ip | hostname | role |
|---|---|---|
| 10.8.26.197 | server1 | 主名字节点 (NodeManager) |
| 10.8.26.196 | server2 | 备名字节点 (SecondaryNameNode) |
| 10.8.26.196 | server2 | 数据字节点 (DataNode) |
2. 软件设施
- jdk1.8.0_102
- scala-2.11.0:
- hadoop-2.7.0
- spark-2.0.2-bin-hadoop2.7:对应 scala 版本不能是 scala-2.11.x
3. HOSTS 设置
在每台服务器的 “/etc/hosts” 文件,添加如下内容:
|
|
4. SSH 免密码登录
Hadoop YARN 分布式集群配置
注:1-8 所有节点都做同样配置
1. 环境变量设置
|
|
变量立即生效
|
|
2. 相关路径创建
|
|
3. 配置 core-site.xml
目录:$HADOOP_HOME/etc/hadoop/core-site.xml
|
|
4. 配置 hdfs-site.xml
目录:$HADOOP_HOME/etc/hadoop/hdfs-site.xml
|
|
5. 配置 mapred-site.xml
目录:$HADOOP_HOME/etc/hadoop/mapred-site.xml
|
|
6. 配置 yarn-site.xml
目录:$HADOOP_HOME/etc/hadoop/yarn-site.xml
|
|
7. 配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh
均在文件开头添加
目录:
- $HADOOP_HOME/etc/hadoop/hadoop-env.sh
- $HADOOP_HOME/etc/hadoop/mapred-env.sh
- $HADOOP_HOME/etc/hadoop/yarn-env.sh
在以上三个文件开头添加如下内容:
|
|
8. 数据节点配置
|
|
9. Hadoop 简单测试
工作目录 master $HADOOP_HOME
|
|
首次启动集群时,做如下操作 [主名字节点上执行]
|
|
检查进程是否正常启动
主名字节点 - server1:
|
|
备名字节点 - server2:
|
|
数据节点 - server3:
|
|
hdfs 与 mapreduce 测试
|
|
执行完成后查看输出,
|
|
也可以通过 UI (http://server1/cluster/apps) 查看:
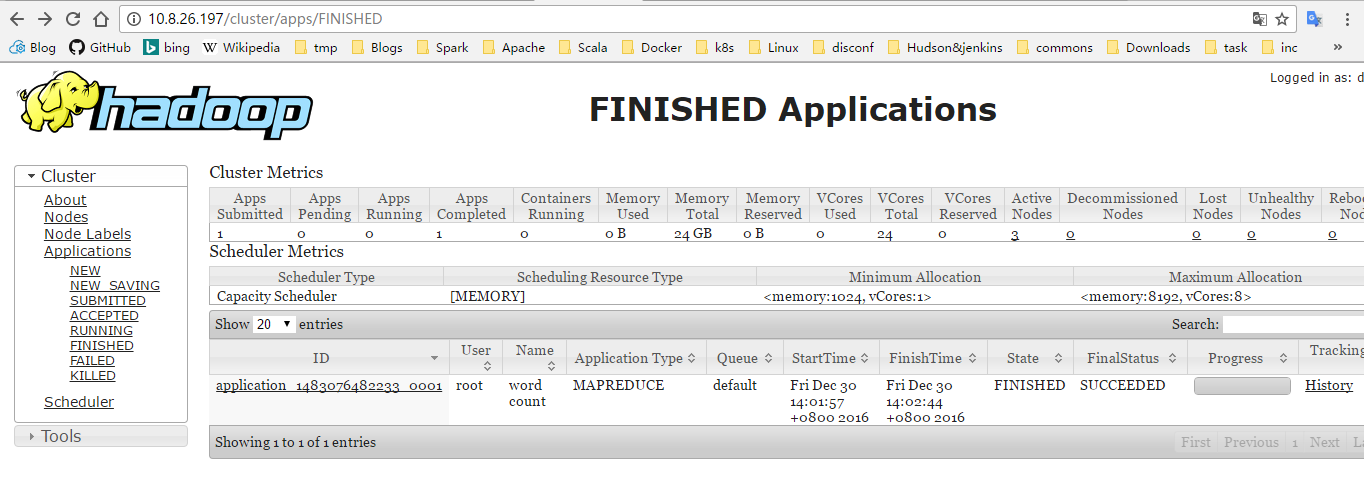
HDFS 信息查看
|
|
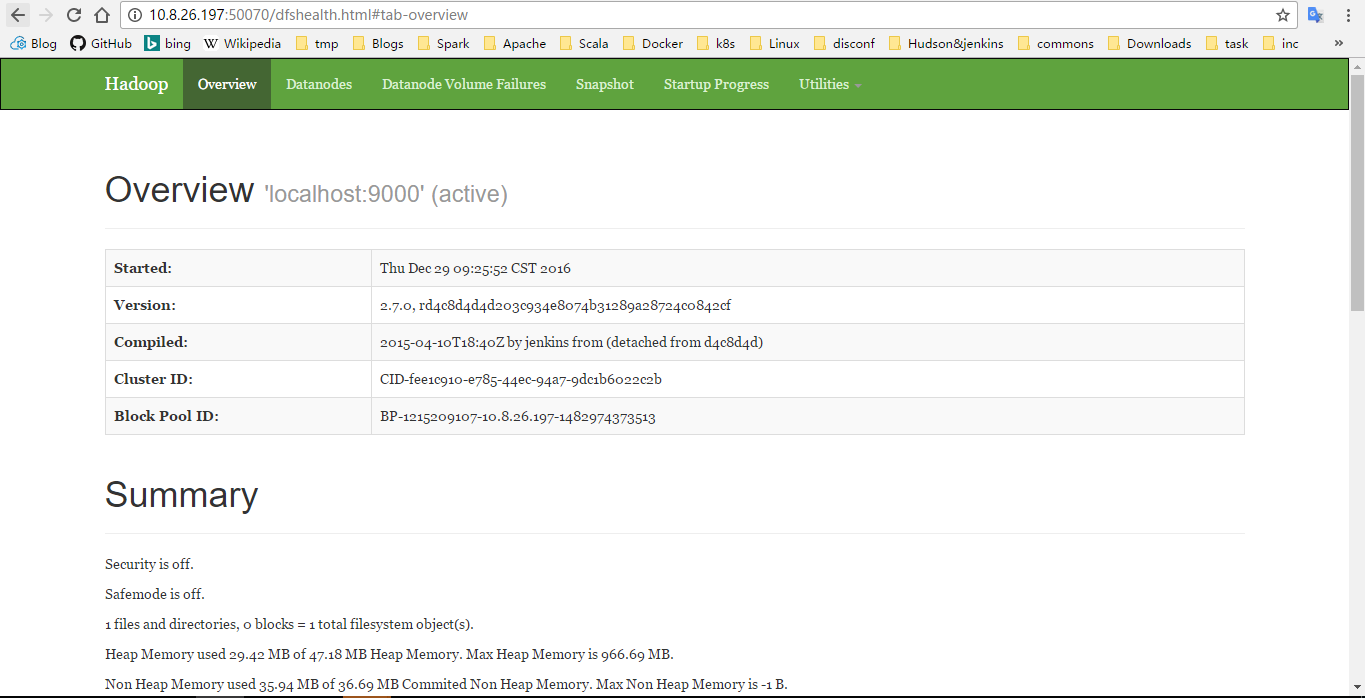
集群的后续维护
|
|
监控页面 URL
Spark 分布式集群配置
注:所有节点都做同样配置
1. Spark 相关配置
Spark 环境变量设置
|
|
|
|
配置 spark-env.sh
|
|
配置 worker 节点的主机名列表
|
|
|
|
其他配置
|
|
在 Master 节点上执行
|
|
检查进程是否启动
在 master 节点上出现 “Master”,在 slave 节点上出现 “Worker”
Master 节点:
|
|
Slave 节点:
|
|
相关测试
监控页面 URL
http://10.8.26.197:8080/ 或 http://server1:8080/
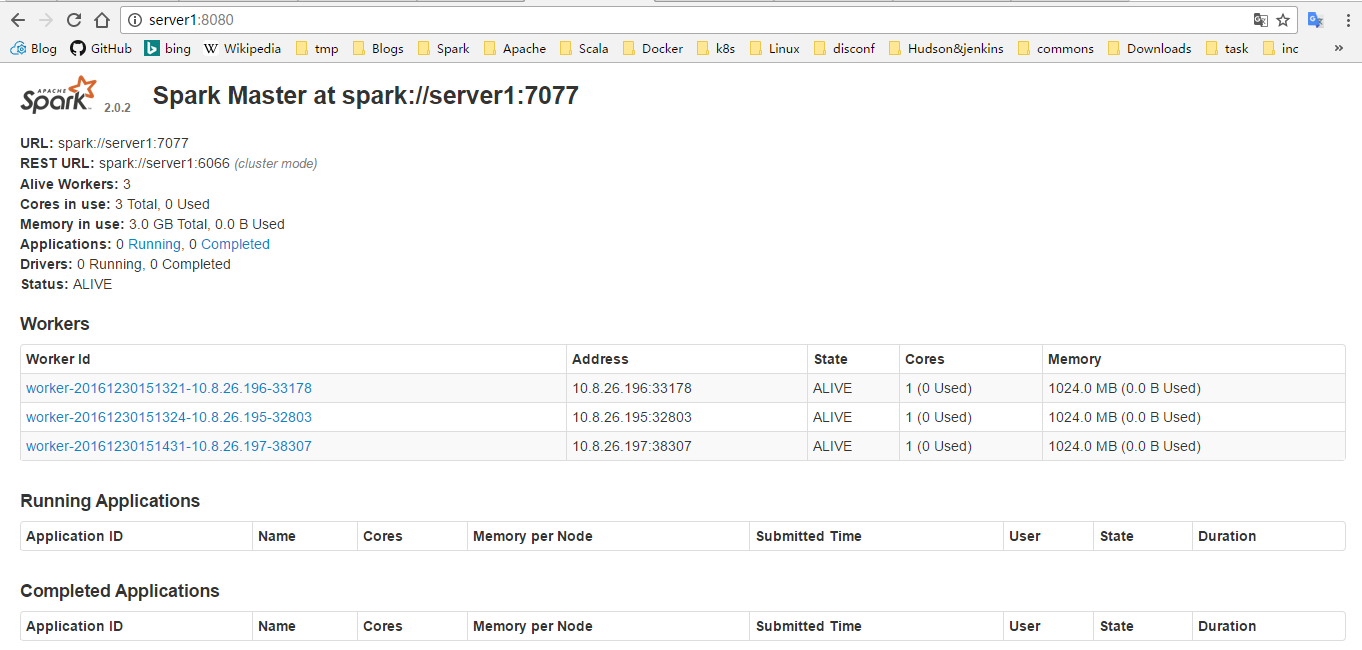
切换到 “$SPARK_HOME/bin” 目录
1. 本地模式
|
|
2. 普通集群模式
|
|
3. 结合 HDFS 的集群模式
工作目录 $SPARK_HOME
|
|
4. 基于 YARN 模式
|
|
执行结果:
$HADOOP_HOME/logs/userlogs/application_*/container*_***/stdout
或
